第一章 计算机概要与技术
计算机系统结构中8个伟大思想
面向摩尔定律的设计:摩尔定律指出单芯片上的集成度每18~24个月翻一番。这说明计算机设计者必须预测芯片设计完成时的工艺水平,而不是开始时的。
使用抽象简化设计:必须发明能够提高产量的技术,否则设计时间也会按照摩尔定律增长。使用抽象表示不同的设计层次,高层次看不到低层次的细节,只能看到简化的模型。
加速大概率事件:大概率事件通常比小概率事件简单,且易于提高。
通过并行提高性能:多线同时处理不同的任务,可以大大减少操作所需时间。
通过流水线提高性能:将各种的功能模块按照某种规则组合成一个能够完成更高级任务的功能模块,其中每一块代表一个流水级,整个线路称为流水线。
通过预测提高性能:通过猜测的方式提前开始某些操作。
存储器层次:将速度最快,容量最小,价格最贵的存储器置于顶层;速度慢但是容量最大,价格便宜的存储器置于底层。类似SSD和机械硬盘的区别。
通过冗余提高可靠性:计算机不仅需要速度快,还需要可靠性。用冗余部件提升系统可靠性,可以在某些部件失效的情况下依旧维持系统运转。
性能
性能的定义
响应时间:也叫执行时间,是计算机完成某任务所需的总时间。
吞吐率:也叫带宽,性能的另一种度量参数,表示单位时间内完成的任务数量。
CPU性能:一个程序的CPU执行时间 = 一个程序的CPU时钟周期数×时钟周期时间。
指令性能:CPI,表示每条指令的时钟周期数的平均值。CPU时钟周期数 = 程序指令数×CPI。
经典的CPU性能公式
CPU时间=指令数×CPI×时钟周期时间=指令数×CPI/时钟频率。
功耗墙
一次翻转:
能耗\propto \frac12 负载电容 × 电压^2;
功耗\propto \frac12 负载电容 × 电压^2 ×开关频率;
多核处理器
阿姆达尔定律:S(N)=\frac1{(1-p)+\frac pN}.
Intel Core i7基准
工作负载:运行在计算机上的一组程序。
基准测试程序:用于比较计算机性能的程序。
MIPS
有一种用MIPS取代时间以度量性能的方法,对于给定的一个程序,MIPS表示为:
MIPS=指令数/(执行时间×10^6)
MIPS作为度量性能的指标存在三个问题:
- MIPS没有考虑指令的能力,因此无法用它比较不同指令集的计算机。
- 在同一计算机上,不同的程序会有不同的MIPS。
第二章 指令:计算机的语言
指令集
计算机语言的基本单词称为指令,一台计算机的全部指令称为该计算机的指令集。
算术运算
add a, b, c # a gets b+c设计原则1:简单源于规整。
计算机硬件的操作数
在MIPS体系结构中,寄存器大小为32位,由于32位为一组的情况经常出现,因此在MIPS体系结构中将其称为字,即计算机中的基本访问单位,与寄存器大小相同。
设计原则2:越小越快。
\$t_i代表临时寄存器,\$s_i代表变量对应的寄存器。
比如:
f=(g+h)-(i+j);其中f,g,h,i,j分配给\$s_0, \$s_1, \$s_2, \$s_3, \$s_4,则编译后的代码为:
add $t0, $s1, $s2
add $t1, $s3, $s4
sub $s0, $t0, $t1存储器操作数
MIPS的算术运算指令支队寄存器进行操作,因此MIPS必须包含在存储器和寄存器之间传送数据的指令。这些指令叫做数据传送指令。
地址:用于在存储器空间中指明某特定数据元素位置的值。
因为MIPS是按字节编址的,所以字的起始地址必须是4的倍数。称为对齐限制。
MIPS采用的是大端编址(big-endian)。
例子:h存放在$s2,数组A的基址存放在$s3,编译下面C语句。
A[12] = h+A[8];lw $t0, 32($s3)
add $t0, $s2, $t0
sw $t0, 48($s3)常数或立即数操作数
指令addi,快速加法指令,加立即数。
下面两种写法效果相同,但是addi指令避免了从存储器中读取数据。
# use addi
addi $s3, $s3, 4
# use reg
lw $t0, AddrConstant4($s1)
add $s3, $s3, $t0包含常数的算术运算指令比从存储器中取数执行速度快很多,且能耗较低。
MIPS将寄存器$zero恒置零,可以简化指令集,符合加速大概率事件思想。
有符号数和无符号数
计算机程序对正数和负数都要计算,所以需要一种方法来区分正数和负数。
符号和幅值表示法(sign and magnitude):增加一个独立的符号位。
这种表示法有若干缺点:
- 符号位位置不明确
- 在计算时不可能提前得知结果的符号,需要计算后额外一步来设置符号
- 一个单独的符号位可能产生正零和负零
二进制补码表示法(two's complement)
计算机中指令的表示
指令在计算机内部形式上和数的表示相同。指令的各部分可以看成一个独立的数,这些数拼接在一起就形成了指令。
MIPS字段
给MIPS字段命名如下:

MIPS指令中各字段名称及含义如下:
- op:指令的基本操作,通常称为操作码(opcode)
- rs:第一个源操作数寄存器
- rt:第二个源操作数寄存器
- rd:用于存放操作结果的目的寄存器
- shamt:位移量
- funct:功能,称为功能码(function code),用于指明op字段中操作的特定变式
设计原则3:优秀的设计需要适宜的折中方案。
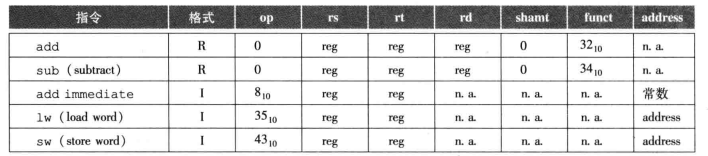
MIPS设计者选择这样的一种折中方案:保持所有的指令长度相同。但不同类型的指令采用不同的指令格式。
例如,上述格式称为R型。另一种指令格式称为I型,I型字段如下所示:

16位的地址字段意味着取字指令可以取相对于基址偏移-2^{15}~2^{15}个字节范围内的任意数据字。
RI格式指令对照:
例:将MIPS汇编语言翻译成机器语言。
下面的C赋值语句:
A[300] = h + A[300];被编译成:
lw $t0, 1200($t1) # $t0 gets A[300]
add $t0, $s2, $t0 # $t0 gets h+A[300]
sw $t0, 1200($t1) # A[300] gets $t0
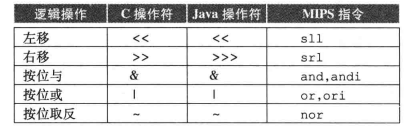
逻辑操作
计算机硬件对过程的支持
过程:根据提供的参数执行一定任务的存储的子程序。
在过程运行中,程序必须遵循以下六个步骤:
- 将参数放在过程可以访问的位置
- 将控制转交给过程
- 获得过程所需的存储资源
- 执行需要的任务
- 将结果的值放在调用程序可以访问的位置
- 将控制返回初始点,因为一个过程可能由一个程序中的多个点调用
使用更多的寄存器
换出寄存器最理想的数据结构是栈。
例:将下面C函数转化为MIPS汇编代码:
int leaf_example(int g, int h, int i, int j){
int f;
f = (g + h) - (i + j);
return f;
}参数变量分别对应$a0到$a3,f对应$s0。
首先以如下标号开始:
leaf_example:下一步需要保存过程中使用的寄存器。这里使用两个临时寄存器,加上一个存储f的寄存器,共三个寄存器。在栈中建立三个字的空间:
addi $sp, $sp, -12
sw $t1, 8($sp)
sw $t0, 4($sp)
sw $s0, 0($sp)然后进行运算:
add $t0, $a0, $a1
add $t1, $a2, $a3
sub $s0, $t0, $t1为了返回f的值,将它复制到返回值寄存器:
add $v0, $s0, $zero返回前,从栈中弹出数据,恢复三个旧值:
lw $s0, 0($sp)
lw $t0, 4($sp)
lw $t1, 8($sp)
addi $sp, $sp, 12末尾处根据跳转寄存器中的返回地址跳转:
jr $raMIPS将18个寄存器分为两组:
- $t0 —— $t9: 10个临时寄存器,在过程调用中不必保存
- $s0 —— $s7: 8个保留寄存器,在过程调用中必须保存
嵌套过程
不调用其他过程的过程称为叶过程。
例:将下列递归C函数转化为MIPS汇编代码:
int fact(int n){
if(n<1)
return 1;
else
return n*fact(n-1);
}n对应参数寄存器$a0,代码如下:
fact:
addi $sp, $sp -8
sw $ra, 4($sp)
sw $a0, 0($sp)
slti $t0, $a0, 1
beq $t0, $zero, L1
addi $v0, $zero, 1
addi $sp, $sp, 8
jr $ra
L1:
addi $a0, $a0, -1
jal fact
lw $a0, 0($sp)
lw $ra, 4($sp)
addi $sp, $sp, 8
mul $v0, $a0, $v0
jr $ra在栈中位新数据分配空间

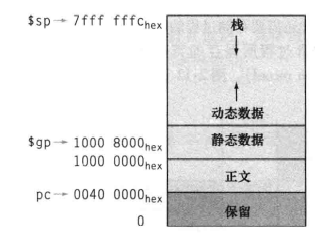
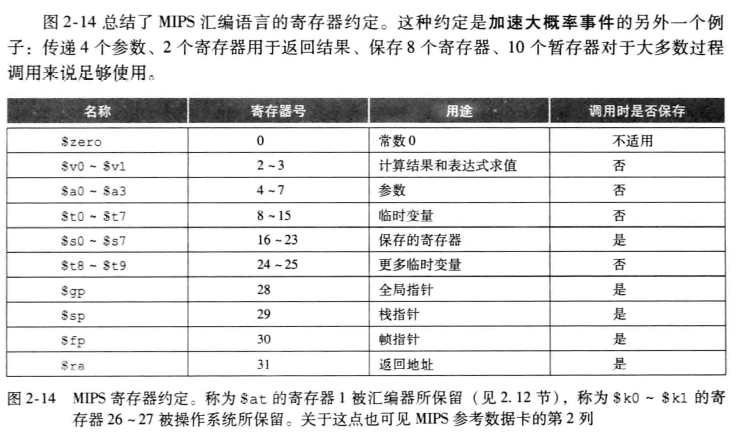
在过程调用前,帧指针fp指向该帧的第一个字,而栈指针指向栈顶。
内存分配
人机交互
字符数据
void strcpy(char x[], char y[]){
int i;
i = 0;
while((x[i] = y[i])!='\0')
i += 1;
}编译后的MIPS汇编代码是什么?
假定数组x,y的基地址存放在a0和a1中,i在s0中。strcpy调整栈指针然后讲保存的寄存器s0保存在栈中。
strcpy:
addi $sp, $sp, -4
sw $s0, 0($sp)为了将i初始化为0,下一条指令将s0置为0。
add $s0, $zero, $zero获取y[i]的地址,此处i不需要乘4,因为y是字节的数组。并用类似的计算方式获取x[i]地址,将字符保存到该地址中。
L1: add $t1, $s0, $a1
lbu $t2, 0($t1)
add $t3, $s0, $a0
sb $t2, 0($t3)如果是字符0则退出循环。否则i+1继续循环。
beq $t2, $zero, L2
addi $s0, $s0, 1
j L1如果不继续循环,还原s0和栈指针,返回。
L2: lw $s0, 0($sp)
addi $sp, $sp, 4
jr $ra这样就完成了C中字符串的复制。
32位立即数和寻址
MIPS指令集中的读取立即数高位指令lui专门用于设置寄存器中常数的高16位,允许后续指令设置常数的低16位。
MIPS跳转指令寻址采用最简单的寻址方式,J型除了6位操作码以外,其余位都是地址字段。
条件分支指令除了规定分支地址外还必须指定两个操作数。
bne $s0, $s1, Exit
如果让程序地址适应16位字段,意味着任何程序都不能大于2^{16},因此另一个可选的办法是指定一个总是加到分支地址上的寄存器,这样分支指令的地址可按如下方式计算:
程序计数器=寄存器+分支地址
寄存器的使用取决于条件分支的使用。
PC相对寻址:一种寻址方式,它将PC和指令中的常数相加作为寻址结果。
因为所有MIPS指令都是4字节长,所以在PC相对寻址时,所加的地址被设计为字地址而非字节地址。相对16位字节地址,字地址的跳转范围扩大了4倍。同样,跳转指令的26位字段也是字地址。
并行与指令:同步
任务之间互相协作,比如某些任务写的结果是其他任务需要读取的值,这种并行执行就需要任务之间的同步,否则就有发生数据竞争的危险,导致读数据错误而引起程序运行结果的改变。
数据竞争:加入来自不同线程的两个访存请求访问同一个地址,它们连续出现,并且至少其中一个是写操作,那么这两个存储访问形成数据竞争。
在计算中,同步机制要以来硬件提供的同步指令。
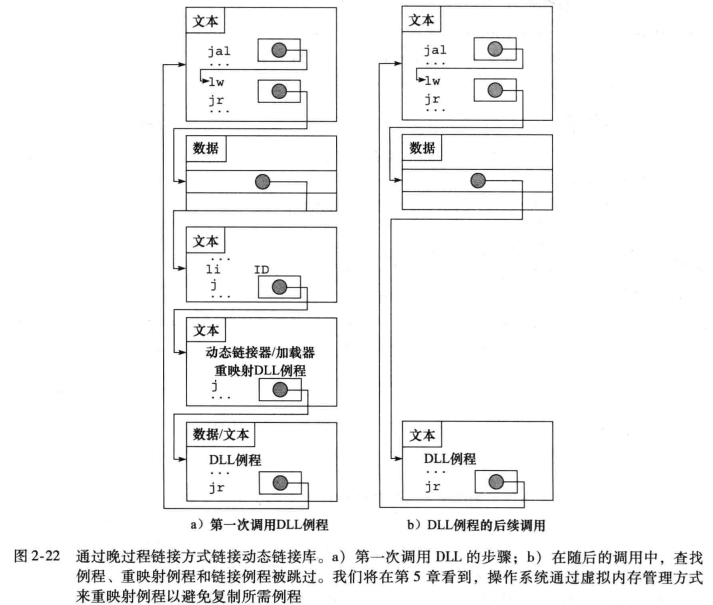
原子操作:是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会切换到其他线程。
在MIPS处理器中这一指令对包括一条叫做链接取数(ll)的特殊取数指令和一条叫做条件存数(sc)的特殊存数指令。
顺序地使用这两条指令:
- 如果ll指定的锁单元的内容在相同地址的条件存数指令执行前已被改变,那么sc失败。
我们定义sc完成以下功能: - 保存寄存器的值,如果执行成功,将reg修改为1,否则修改为0。
again: addi $t0, $zero, 1
ll $t1, 0($s1)
sc $t0, 0($s1)
beq $t0, $zero, again #branch if store fails
add $s4, $zero, $t1在ll和sc两条指令之间的任何时候有处理器插入,并且修改了锁单元的值,sc都会将t0置零,导致这段程序重新执行。
翻译并执行程序
汇编伪指令
伪指令是汇编语言指令的一个变种。
总的来说,伪指令使MIPS拥有比硬件所实现的更为丰富的汇编语言指令集。唯一的代价是保留了一个由汇编器使用的寄存器at。
编译器
编译器将程序翻译成机器指令,并且提供从碎片中构造完整项目的信息。
MIPS内存分配
链接器
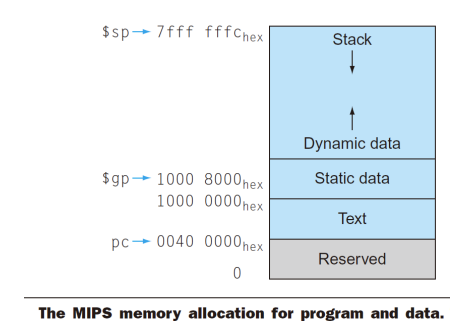
链接器,也称链接编辑器。它是一个系统程序,把各个独立汇编的机器语言程序组合起来,并解决所有未定义的标记,最后生成可执行文件。
链接器的工作分为三个步骤:
- 将代码和数据模块象征性地放入内存
- 决定数据和指令标签的地址
- 修补内部和外部引用
链接器使用每个目标模块中的重定位信息和符号表,来解析所有未定义标签。
加载器
把目标程序装载到内存中以准备运行的系统程序。
动态链接库
在程序执行过程中才被链接的库例程。
以C排序作为完整的例子
swap过程
查看C函数swap:
void swap(int v[], int k){
int temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}分配寄存器
在MIPS中,实现参数传递通常使用寄存器a0, a1, a2, a3。由于swap只需要两个参数v和k,因此分配a0, a1给它们。temp分配到t0中。
为过程体生成代码
sll $t1, $a1, 2
add $t1, $a0, $t1
lw $t0, 0($t1)
lw $t2, 4($t2)
sw $t2, 0($t1)
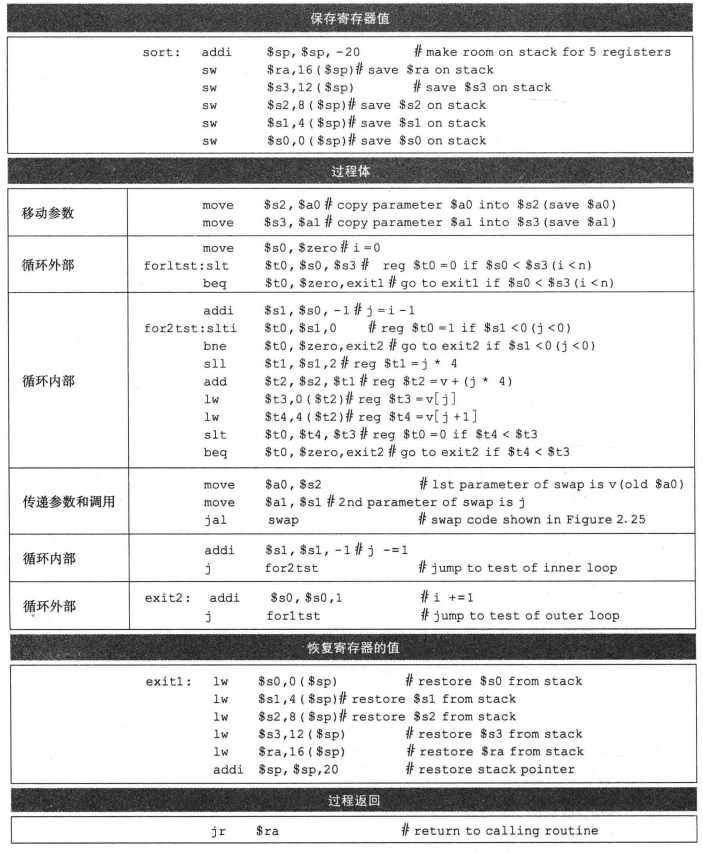
sw $t0, 4($t1)sort过程
排序C程序:
void sort(int v[], int n){
int i, j;
for(i = 0; i < n; i++){
for(j = i - 1; j >= 0 && v[j] > v[j+1]; j = 1)
swap(v, j)
}
}
数组与指针
先看两个将数组清零的C过程:
clear1(int array[], int size){
int i;
for(i = 0; i < size; i+=1)
array[i] = 0;
}
clear2(int *array, int size){
int *p;
for(p = &array[0]; p < &array[size]; p = p+1)
*p = 0;
}用数组实现clear
move $t0, $zero
loop1:
sll $t1, $t0, 2
add $t2, $a0, $t1
sw $zero, 0($t2)
addi $t0, $t0, 1
slt $t3, $t0, $a1
bne $t3, $zero, loop1用指针实现clear
move $t0, $a0
loop2:
sw $zero, 0($t0)
addi $t0, $t0, 4
sll $t1, $a1, 2
add $t2, $a0, $ti
slt $t3, $t0, $t2
bne $t3, $zero, loop2第三章 计算机的算术运算
加法和减法


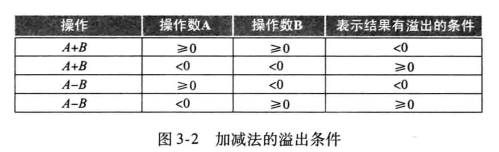
计算机设计者必须提供一种方法,能够在某些情况下忽略溢出的发生,而在另一些情况下能进行溢出的检测。MIPS采用两种类型的算术指令来解决这个问题:
- add,addi,sub在溢出时产生异常
- addu,addiu,subu在发生溢出时不产生异常
乘法

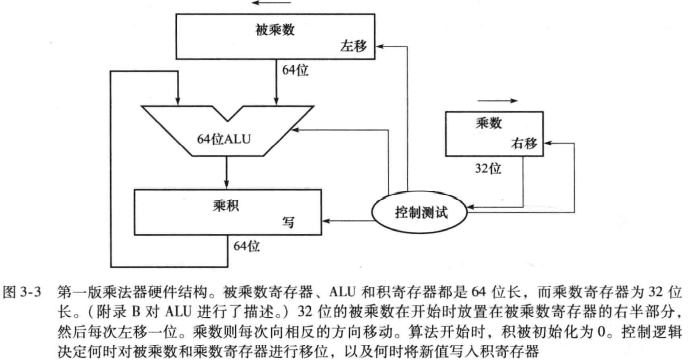
顺序的乘法算法和硬件
改进结构:
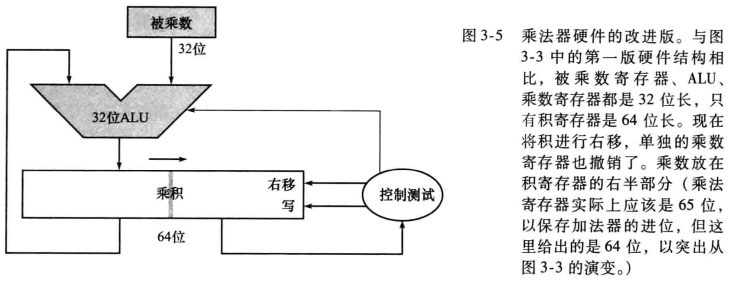
这里的乘积,左半侧32位存放乘积结果,右半侧存放乘数,每位乘法将乘积寄存器整体右移,右移32次的结果就是最终的乘积。
有符号乘法
记住原来的符号位,转化为无符号乘法。
更快速的乘法
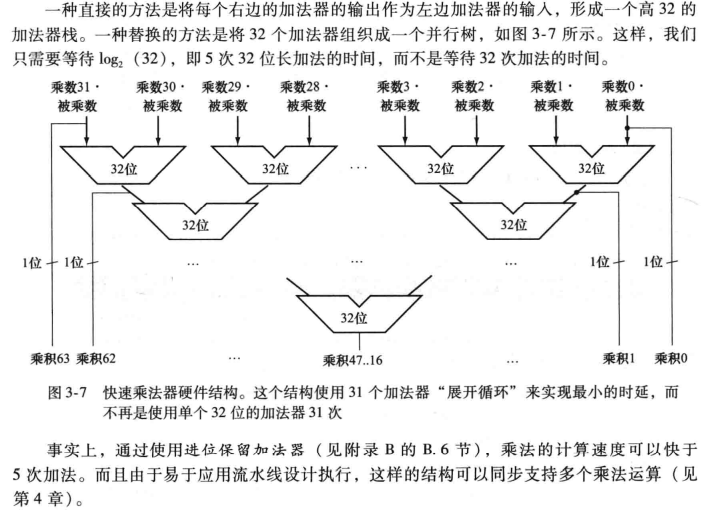
再第一层结果输入第二层时,第一层就可以接纳新的乘法运算,以提升效率。
除法

除法算法及其硬件结构
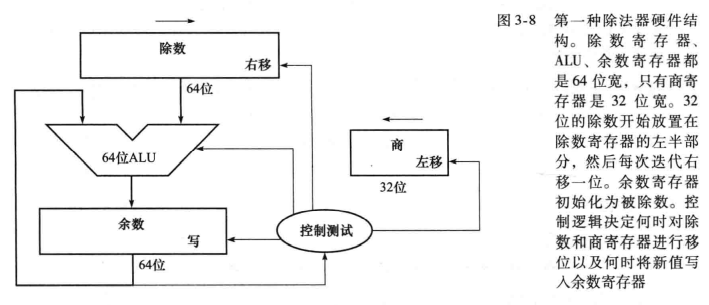

有符号除法
有符号除法一个比较麻烦的地方是必须设置余数的符号。
保持被除数的符号和余数的符号相同可以避免异常情况。
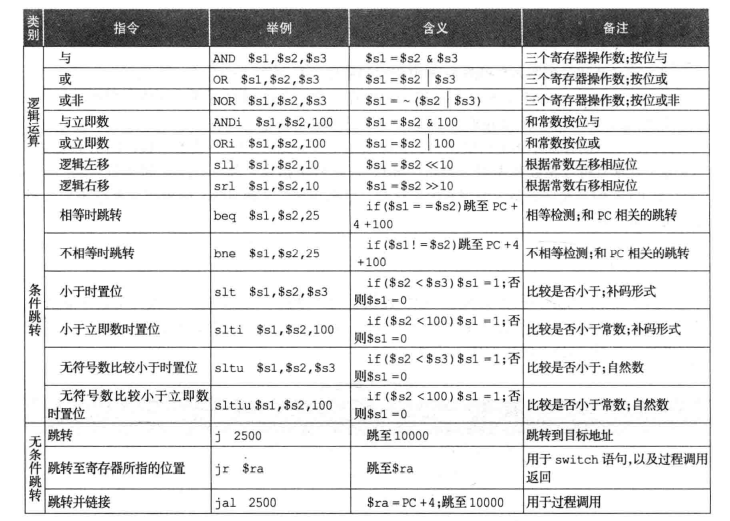
MIPS运算、数据传输和跳转指令

浮点运算
浮点表示
一个采用科学记数法表示的数,如果没有前导零,且小数点左边只有一位整数,则称之为规格化数。例如,1.0×10^{-9}就是规格化科学记数。
尾数:位于浮点数的尾数字段,其值在0和1之间。
指数:位于浮点数的指数字段,表示小数点的位置。

上溢:正的指数太大导致指数域放不下的情况。
下溢:负的指数太大导致指数域放不下的情况。
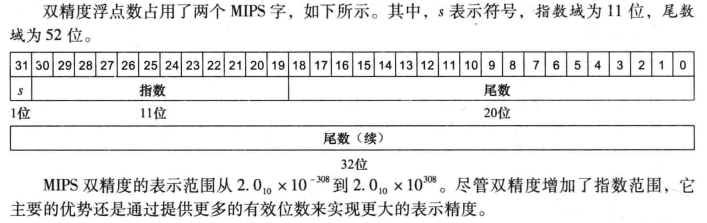
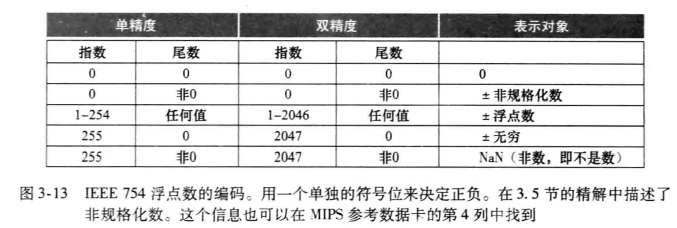
IEEE754浮点数表示:

浮点体系结构:
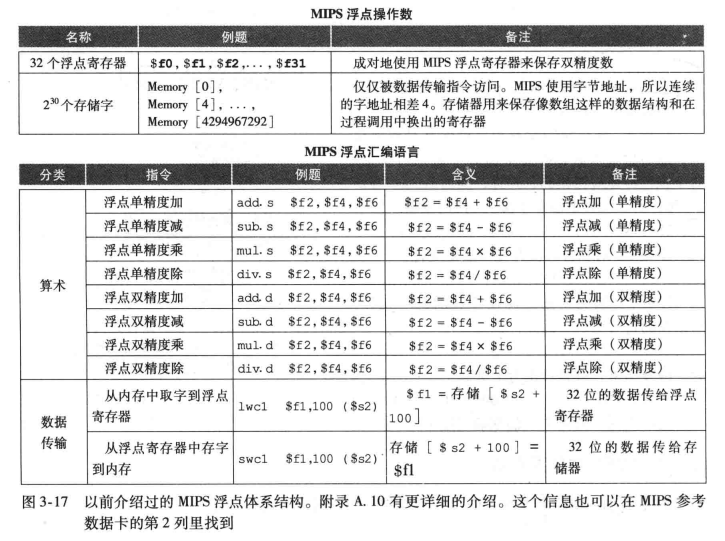
算术精确性
保护位:在浮点数中间计算中,在右边多保留的两位中的首位;用于提高舍入精度。
舍入位:第二位,使浮点中间结果满足浮点格式,得到最接近的数。
总而言之,对于需求的精度,计算的时候多加两位,最后再舍入以保证精度。而不是舍入,计算,再舍入。
尾数最低位:再实际数和能表达的数之间的有效数最低位上的误差位数。
子字并行
许多视频和音频应用中通常对这类数据的向量做相同的操作。通过在128位内对进位链进行分割,处理器可以同时对16给8位、8个64位...的运算同时进行并行操作。
加速矩阵乘法
未经优化的双精度矩阵乘法的C语言版本:
void dgemm(int n, double *A, double *B, double *C){
for(int i = 0; i < n; ++i){
for(int j = 0; j < n; ++j){
double cij = C[i+j*n];
for(int k = 0; k < n; k++)
cij += A[i+k*n]*B[k+j*n];
C[i+j*n] = cij;
}
}
}
优化方法使用的_m256d数据类型,用来告诉编译器变量将保存4个双精度浮点值。内蕴函数_mm256_loas_pd()使用AVX指令从矩阵C中并行取出4个双精度浮点数到c0。

加减法注意事项
整数右移指令不能代替与2的幂次数相除
在有符号整数上,比如-5除以4,商应该为-1,但是右移会变成1073431822。如果右移在扩展后移入1,答案是-2,也不是-1。
浮点加法不能使用结合律
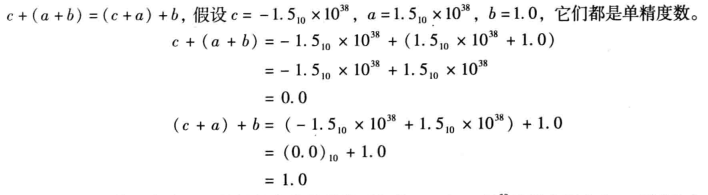
第四章 处理器
逻辑设计的一般方法
MIPS实现中的数据通路功能部件包括两种不同的逻辑单元:处理数据值的单元和存储状态的单元。处理数据值的单元都是组合单元,他们的输出只取决于当前的输入。
如果一个单元带有内部存储功能,它就称为状态单元,状态单元描述了计算机的状态。
一个状态单元至少有两个输入和一个输出,两个必要的输入为要写入单元的数据值决定何时写入的时钟信号。
包含状态的逻辑部件又被称为时序的,因为他们的输出由输入和内部状态共同决定。
时钟方法
时钟方法规定了信号可以读出和写入的时间。
规定信号读写的时间非常重要,因为若一个信号同时被读出和写入,则所读出的信号可能是写入前的值,也可能是新写入的值,甚至是两者的混合。
建立数据通路
设计数据通路比较合理的方法是首先分析执行每种MIPS指令时需要哪些操作部件。
数据通路部件:一个用来操作或保存处理器中数据的单元。在MIPS实现中,数据通路部件包括指令存储器、数据存储器、寄存器堆、ALU和加法器。
程序计数器:存放下一条将要被执行指令的地址的寄存器。

现在讨论R型指令,这类指令读两个寄存器,对它们的内容进行ALU操作,再写回结果。这个指令包括and,sub,AND,OR和slt指令。
处理器的32个通用寄存器位于一个叫做寄存器堆的结构中。
寄存器堆:包含一系列寄存器的状态单元,可以通过提供寄存器号进行读写。
R型指令有3个寄存器操作数。
为读出一个数据字,寄存器堆需要输入一个要读的寄存器号和一个从寄存器堆读出结果的输出指示。
为写入一个数据字,寄存器堆要有两个输入,寄存器号和数据。
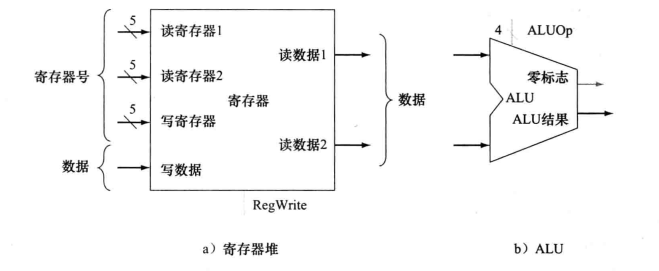
比如指令
add $t0, $t1, $t2对于寄存器堆来说,需要输入三个寄存器号,并且读取t1和t2的两个数据,将数据经过ALU操作之后,作为写的数据输入寄存器堆。
还需要一个单元将16位的偏移地址符号扩展为32位的带符号值,以及一个保存读出或写入数据的存储单元。
beq指令有3个操作数,其中两个为寄存器,用于比较是否相等,另一个是16位偏移量,用于计算相对于分支指令所在地址的目标分支地址。
流水线概述
流水线:一种实现多条指令重叠执行的技术。
比如一个输入,需要从处理方法A到处理方法B再到处理方法C完成后输出。那么当第一次输入经过处理方法A完成,输入处理方法B时,第二次输入就可以启用处理方法A了。
对于单个输入,流水线并不会提升效率。但是对于多个输入,流水线可以缩短数据被处理的时间,从而整体上提升效率。

为了使问题具体化,我们先创建一个流水线结构。假设单周期模型中所有指令的执行都花费一个时钟周期。假设主要功能单元的操作时间为:
- 存储器访问:200ps
- ALU操作:200ps
- 寄存器堆的读写:100ps


所有的流水级都只花费一个时钟周期的时间,因此,时钟周期必须能够满足最慢操作的执行需要。
如果流水线各阶段操作平衡,那么流水线机器上的指令执行时间为:
t_{流} = \frac{t_{非流}}{s}
这里的s为流水线级数。
即,再理想情况且有大量指令的情况下,流水线带来的加速比与流水线级数近似相同。
面向流水线的指令集设计
第一,所有MIPS指令的长度都是相同的。
第二,MIPS只有很少的集中指令格式,并且每一条指令中的源寄存器字段位置都是相同的。
第三,MIPS中存储器操作数仅出现在存取指令中。
第四,所有操作数必须再存储器中对齐。
MIPS流水线
- IF:取指令
- ID:解码指令,读寄存器
- EX:执行操作或者计算地址
- MEM:数据访问
- WB:写寄存器
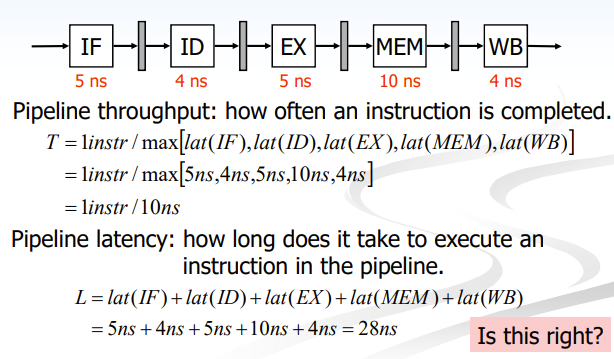
每个流水级所耗时间和顺序如图所示。其吞吐量为每10ns一条。执行这条指令的耗时为28ns。

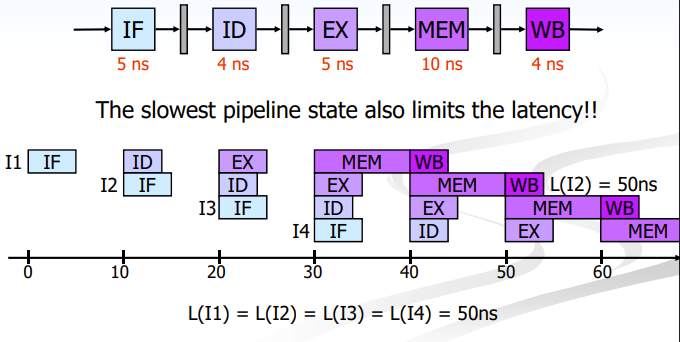
但是对于流水线而言,执行四条指令的时间就不能用简单的加法来计算了。我们需要将每个相同类型的操作分开,确保没有多个同类型的指令在同时执行。如图,可以得出4条指令的完成时间为43ns。
但这样又产生了一个问题,这是一个不平衡的流水线。计算机很难判断下一步的流水级应该在何时执行,以避免与上一条指令的同类流水级发生冲突。因此在设计时,我们采用将每一个流水级的时钟周期与最长流水级时钟周期对齐的方式。
如果把最长的MEM操作分为两段,加入一个流水级进去,将10变为5和5,则可以更好地优化流水线。
流水线冒险
结构冒险
结构冒险,即因缺乏硬件支持而导致指令不能在预定的时钟周期内执行的情况。
如果流水线结构只有一个存储器,而非两个。在第一条指令存数据的时候,后续指令读数据,虽然是不同的流水级,但是占用的是同一个硬件设备。就会发生结构冒险。
数据冒险
数据冒险发生在由于一条指令必须等待另一条指令的完成二造成流水线暂停的情况。
add $s0, $t0, $t1
sub $t2, $s0, $t3上述代码中的第二条指令依赖于第一条指令的数据计算。
一种解决数据冒险的方法称为前推,如果从内部寄存器直接提取数据,就可以提前执行下一条指令。
当一条R型指令之后紧跟着一条需要使用其结果的装载指令时,即使使用了旁路机制也要进行一次阻塞。
控制冒险
控制冒险发生在获取下一条指令取决于分支结果的时候,可能获取不到想要的指令。
通过阻塞可以保证正常工作,即使用串行的方式操作,重复这一过程直到找到正确的指令为止。
如果可以加入足够多的硬件,使得在流水线的第二季能测试寄存器、计算分支地址并更新PC,就可以使用分支预测的方法。它预测分支结果并立即沿着某方向执行,而不是等待。
流水线数据通路及其控制

图中有两个从右到左的流,一个是写回阶段,将数据写回数据通路中间的寄存器堆。另一个是PC下个值需要在自增和MEM的分支地址之间选择。
这两个数据流不会影响当前指令,只有后面的指令会受到这种反向数据活动的影响。
第一个流会导致数据冒险;第二个流会导致控制冒险。
在每个阶段中间插入一个阶段寄存器,用于存储上一个时钟周期执行的指令。这样,在这个阶段执行的正确信息会被保存。
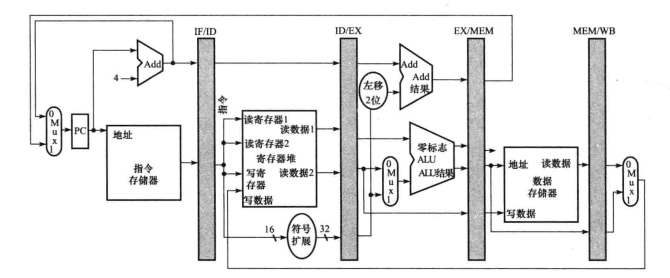
阶段寄存器的变化只在时钟的边缘发生。
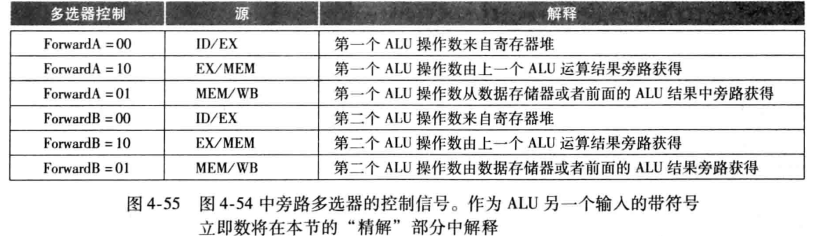
解决数据冒险:旁路和阻塞
分析下列指令序列:
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
and $14, $2, $2
sw $15, 100($2)画出下列流水线示意图:

分析指令序列可以看到,第二条指令的rs需要第一条指令的运算结果rd,在同一时钟周期内,产生的冒险为EX/MEM.Rd = ID/EX.Rs数据冒险。因此需要从第一条指令的EX/MEM流水线寄存器构造通往第二条指令的ID/EX流水线寄存器的旁路。
第三条指令的rt需要第一条指令的运算结果rd,因此产生的冒险为MEM/WB.Rd = ID/EX.Rt数据冒险。同理构造旁路。
然而,旁路不能解决所有的冒险。因为某些指令可能不写回寄存器。一种简单的解决方法就是检测RegWrite是否是活动的(即为true)。并且Rd不能为0。如果满足以上条件,那么就表示需要旁路。
但是还有另外一种无法通过旁路解决问题的情况,比如下列代码:
lw $2, 20($1)
and $4, $2, $5
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7画出下列流水线示意图:

因为在第一条取数指令中,数据是在第四个时钟周期从内存中读出的,但是下一条运算的时间在第三个时钟周期。这是旁路无法解决的回溯问题。因此需要插入一条nop指令保证流水线的正确运转。
解决控制冒险
控制冒险发生在获取下一条指令取决于分支结果的时候,可能获取不到想要的指令。
比如下例:
beq $1, $3, next
and $12, $2, $5
or $13, $6, $2
add $14, $2, $2
next:
lw $4, 50($7)因为流水线需要顺序执行的指令,分支结构明显破环了顺序,因此若要解决控制冒险,必须考虑如何将分支结构转化为顺序结构。
假定分支不发生
采用阻塞的方法会导致流水线效率过低。如果综合分支不发生的可能性和丢弃指令的代价,假定分支不发生,直接顺次执行的方法可以优化流水线的效率。如果分支实际上发生了,那么就丢弃已经执行过的指令。
为了丢弃指令,只需要将最初的控制信号设置为0。
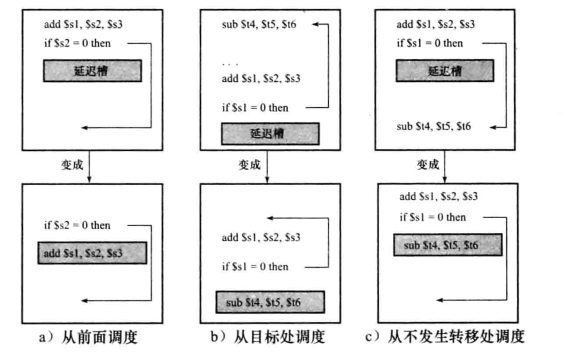
缩短分支的延迟
将分支执行提前到ID级。
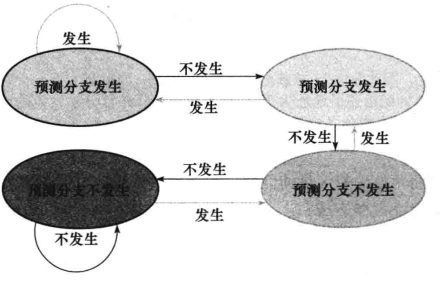
动态分支预测
假定分支不发生是一种粗略的分支预测方法。从时钟周期的角度来说,如果流水线深度较深,分支的代价就会增加。
一种策略是通过查找指令的地址观察上一次执行该指令时分支是否发生,如果上次发生,就从上次分支发生的地方开始取新的指令。这种技术称为动态分支预测。
分支预测缓存:也称为分支历史记录表。一小块按照指令的低位地址索引的存储器区,其中包括一位或多位数据用以说明最近是否发生过分支。
使用一位的简单预测具有性能上的缺陷,如果一个分支未发生就会导致两次的预测错误。
还可以使用分支延迟时间槽的方法解决控制冒险。在分支指令后面插入一条无关紧要的指令取代原本的nop指令。
异常
MIPS体系结构中的异常处理
在异常程序计数器(EPC)中保存出错指令的地址,并把控制权交给操作系统的特定地址。
为了处理异常,还需要知道引起异常的原因。有两种方法表示产生异常的原因:
- 状态寄存器,其中一个字段记录原因
- 向量中断,控制权被转移到有异常原因决定的地址处
在流水线实现中的异常
流水线中的异常可以视为另一种形式的控制冒险。
指令级并行
流水线挖掘了指令间潜在的并行性,被称为指令级并行。
有两种方法可以增加潜在的指令级并行程度,第一种是增加深度,第二种是复制计算机内部部件的数量,使得每个流水级可以启动多条指令,称为多发射。
不同的实现方式将导致决策是在编译时进行的还是在执行时进行的,两种方式分别称为静态和动态多发射。
多发射流水线必须处理以下两个问题:
- 往发射槽发射多条指令
- 处理数据冒险和控制冒险
推测的概念
推测:一种编译器或处理器推测指令结果,以消除执行其他指令对该结果依赖的方法。